![]()
![]()
splitGraph is an R package for representing biomedical
dataset structure as a typed dependency graph so that leakage-relevant
relationships can be made explicit, validated, queried, and converted
into deterministic split constraints.
It does not fit models, run preprocessing pipelines, or generate resamples by itself. Its job is to encode dataset structure before evaluation so that overlap, provenance, and time-ordering assumptions are inspectable instead of implicit.
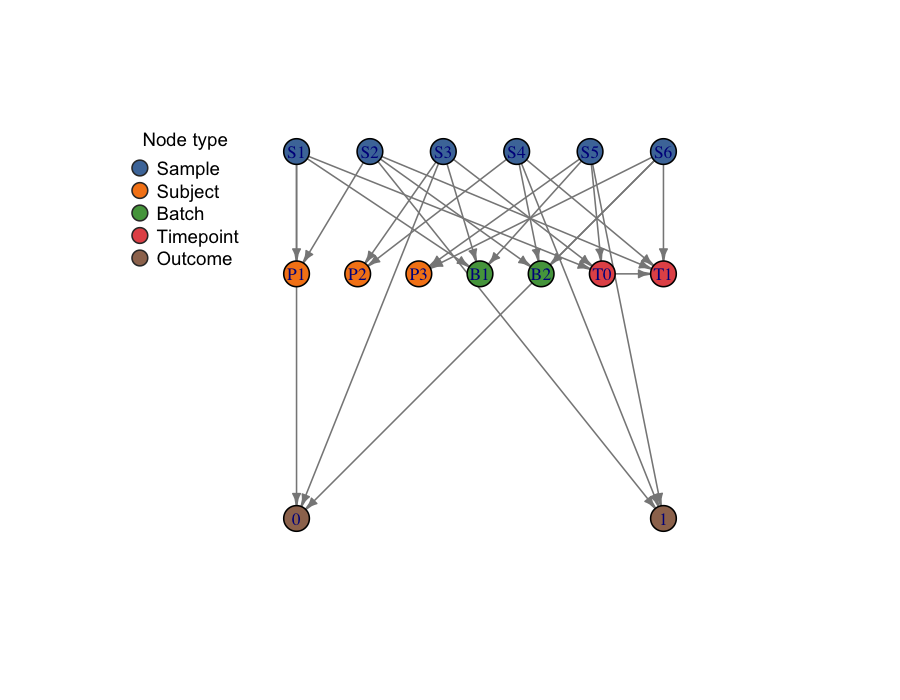
The plot above shows six samples (blue) that share three subjects
(orange), two batches (green), two timepoints (red), and two outcome
classes (brown). A plain vfold_cv on this dataset would
violate subject, batch, and time structure at the same time —
and that is exactly what the graph is designed to make visible.
In biomedical evaluation workflows, leakage often comes from dataset structure rather than obvious coding mistakes. Samples may share:
If those relationships are not modeled explicitly, a train/test split can look correct while still violating the intended scientific separation.
splitGraph makes those dependencies first-class
objects.
Does:
graph_from_metadata()igraphvalidation_overrides mechanism for explicit
exceptionsquery_paths())relatedness / spatial modes group by
transitive closure over thresholded edges built with
relatedness_edges_from_kinship() /
spatial_edges_from_coords())split_specdependency_graph and
split_spec so handoff objects are portable across sessions
and languages (write_*() / read_*(), requires
jsonlite)plot() method with per-type colors and a
node-type legendprint(), summary(), and
as.data.frame() on all core S3 objectsDoes not:
rsample does that)The package is intentionally narrow: dataset dependency structure for leakage-aware evaluation design.
splitGraph sits one layer above execution. It represents
dependency structure, validates it, and emits a neutral
split_spec — and stops there. It has zero
resampling or modeling dependencies and no runtime dependency on any
downstream package.
| splitGraph owns | Downstream consumer owns |
|---|---|
| Typed dependency graph + validation | Generating resamples / folds |
| Deriving split constraints | Stratified splitting, purge/embargo execution |
Emitting + validating the split_spec IR |
Model fitting, tuning, performance auditing |
| Carrying stratum / ordering / blocking annotations | Statistical leakage evidence (ΔLSI, permutation gaps) |
The reference consumer is bioLeak:
bioLeak::as_leaksplits(spec, data, outcome) turns a
splitGraph split_spec into an executable, leakage-audited
split plan. Because split_spec is a documented,
tool-agnostic contract (with a formal JSON Schema and a Python reference
consumer), other tools — an rsample adapter, the shipped
Python reader driving scikit-learn — can consume it equally. A contract
test (Suggests: bioLeak, skipped if absent) pins this seam
so neither side breaks it silently.
From GitHub:
install.packages("remotes")
remotes::install_github("selcukorkmaz/splitGraph")To use the JSON serialization API, also install
jsonlite:
install.packages("jsonlite")The fastest path is graph_from_metadata(), which
auto-detects canonical columns in a metadata frame and assembles a
validated dependency_graph:
library(splitGraph)
meta <- data.frame(
sample_id = c("S1", "S2", "S3", "S4", "S5", "S6"),
subject_id = c("P1", "P1", "P2", "P2", "P3", "P3"),
batch_id = c("B1", "B2", "B1", "B2", "B1", "B2"),
timepoint_id = c("T0", "T1", "T0", "T1", "T0", "T1"),
time_index = c(0, 1, 0, 1, 0, 1),
outcome_id = c("ctrl", "case", "ctrl", "case", "case", "ctrl")
)
g <- graph_from_metadata(meta, graph_name = "demo")
plot(g)
validation <- validate_graph(g)
subject_constraint <- derive_split_constraints(g, mode = "subject")
spec <- as_split_spec(subject_constraint, graph = g)
validate_split_spec(spec)
summarize_leakage_risks(g, constraint = subject_constraint, split_spec = spec)
# Persist the spec for a downstream consumer (R or non-R):
path <- tempfile(fileext = ".json")
write_split_spec(spec, path)
spec2 <- read_split_spec(path)For full control over node labels, attribute columns, and the
feature-set provenance edges, use create_nodes() /
create_edges() / build_dependency_graph()
directly. graph_from_metadata() auto-builds the nine
sample-rooted canonical edges (including
sample_collected_at_site from a site_id
column, sample_located_in_region from a
region_id column, and sample_run_on_platform
from a platform_id column),
timepoint_precedes, and the appropriate outcome edge
(sample_has_outcome by default, or
subject_has_outcome when
outcome_scope = "subject"). The
featureset_generated_from_study and
featureset_generated_from_batch edges always require the
explicit constructor path.
split_spec is the tool-agnostic handoff object produced
by as_split_spec(). splitGraph does not know
about any particular resampling package — downstream consumers are
expected to provide their own adapters so that splitGraph
stays neutral and has no runtime dependency on them.
The typical end-to-end flow is:
graph_from_metadata(meta) → typed
dependency_graphderive_split_constraints(g, mode = ...) →
split_constraintas_split_spec(constraint, graph = g) →
split_specwrite_split_spec(spec, path) → JSON, for
cross-session or cross-language handoffThe sample_data frame carried by split_spec
exposes exactly what an adapter needs: sample_id for
joining against the observation frame, group_id for grouped
resampling, batch_group / study_group for
blocking, and order_rank for ordered evaluation. An adapter
can be built on top of, for example,
rsample::group_vfold_cv() (grouped CV keyed to
group_id) or rsample::rolling_origin()
(ordered evaluation keyed to order_rank).
For three small, self-contained adapter examples (a base-R LOGO
adapter, plus illustrative rsample::group_vfold_cv() and
rsample::rolling_origin() adapters), see the
Adapter cookbook vignette:
vignette("adapter-cookbook", package = "splitGraph")split_spec is a language-neutral interchange format. A
pure-Python reference consumer ships in inst/python
(splitspec) that reads the JSON and drives scikit-learn
GroupKFold / StratifiedGroupKFold /
TimeSeriesSplit; a conformance check asserts the Python
grouping matches R’s grouping_vector(). The
cross-language handoff vignette walks the full R → JSON
→ Python → scikit-learn path:
vignette("cross-language-handoff", package = "splitGraph")Sample, Subject, Batch,
Study, Timepoint, Assay,
FeatureSet, Outcome, Site,
Region, Platformsample_belongs_to_subjectsample_processed_in_batchsample_from_studysample_collected_at_timepointsample_measured_by_assaysample_uses_featuresetsample_has_outcomesubject_has_outcomesample_collected_at_sitesample_located_in_regionsample_run_on_platformassay_uses_platformsubject_related_tosample_adjacent_totimepoint_precedesfeatureset_generated_from_studyfeatureset_generated_from_batchgraph_node_set, graph_edge_set,
dependency_graph, depgraph_validation_report,
graph_query_result, split_constraint,
split_spec, split_spec_validation,
leakage_risk_summary.
| Layer | Functions |
|---|---|
| Ingestion and construction | ingest_metadata(), graph_from_metadata(),
create_nodes(), create_edges(),
build_dependency_graph(), dependency_graph(),
as_igraph() |
| Validation | validate_graph() (with
validation_overrides),
validate_split_spec() |
| Queries | query_node_type(), query_edge_type(),
query_neighbors(), query_paths() (capped by
default), query_shortest_paths(),
detect_dependency_components(),
detect_shared_dependencies() |
| Constraint derivation | derive_split_constraints(),
grouping_vector() |
| Split-spec translation | as_split_spec(),
summarize_leakage_risks() |
| Serialization (JSON) | write_dependency_graph(),
read_dependency_graph(), write_split_spec(),
read_split_spec() |
query_node_type(g, "Subject")
query_edge_type(g, "sample_processed_in_batch")
query_neighbors(g, node_ids = "sample:S1", edge_types = "sample_belongs_to_subject")
detect_shared_dependencies(g, via = "Batch")
detect_dependency_components(g, via = c("Subject", "Batch"))subject_constraint <- derive_split_constraints(g, mode = "subject")
batch_constraint <- derive_split_constraints(g, mode = "batch")
study_constraint <- derive_split_constraints(g, mode = "study")
time_constraint <- derive_split_constraints(g, mode = "time")
site_constraint <- derive_split_constraints(g, mode = "site")
region_constraint <- derive_split_constraints(g, mode = "region")
platform_constraint <- derive_split_constraints(g, mode = "platform")
assay_constraint <- derive_split_constraints(g, mode = "assay")
strict_composite <- derive_split_constraints(
g, mode = "composite", strategy = "strict",
via = c("Subject", "Batch")
)
rule_based_composite <- derive_split_constraints(
g, mode = "composite", strategy = "rule_based",
priority = c("batch", "study", "subject", "time")
)Pairwise (thresholded) relations are built from a continuous similarity signal and then grouped by transitive closure over the surviving edges:
# Genetic relatedness: keep subject pairs with kinship >= 0.1.
kin <- data.frame(id1 = "P1", id2 = "P2", kinship = 0.25)
rel_edges <- relatedness_edges_from_kinship(kin, threshold = 0.1)
# Spatial proximity: connect samples within a radius.
coords <- data.frame(sample_id = c("S1", "S2", "S3"), x = c(0, 1, 9), y = c(0, 1, 9))
adj_edges <- spatial_edges_from_coords(coords, radius = 2)
# Combine with the base node/edge sets in build_dependency_graph(), then:
relatedness_constraint <- derive_split_constraints(g, mode = "relatedness")
spatial_constraint <- derive_split_constraints(g, mode = "spatial")Both core handoff objects can be written to a stable,
schema-versioned JSON format and read back, so a
dependency_graph or split_spec is portable
across R sessions and across language boundaries.
graph_path <- tempfile(fileext = ".json")
spec_path <- tempfile(fileext = ".json")
write_dependency_graph(g, graph_path)
write_split_spec(spec, spec_path)
g2 <- read_dependency_graph(graph_path)
spec2 <- read_split_spec(spec_path)Both formats have a formal JSON Schema (Draft 2020-12) shipped in
inst/schema/, and every written file references it via a
$schema key. Validate a handoff file against the contract
with validate_graph_json() /
validate_split_spec_json(). Each file also carries a
schema_version; the major version is the
compatibility boundary, so files sharing the installed major load
silently while a differing major warns.
migrate_dependency_graph_json() /
migrate_split_spec_json() upgrade an older file to the
current version in place. NA values in
sample_data round-trip as JSON null. The
jsonlite package (a Suggests dep) must be
installed.
plot(g) renders a typed, layered layout with per-type
node colors and an auto-generated node-type legend. Layers: Sample
(top), peer dependencies (Subject / Batch / Study / Timepoint) in the
middle band, Assay / FeatureSet next, Outcome (bottom).
plot(g) # typed layered layout (default)
plot(g, layout = "sugiyama") # alternative hierarchical layout
plot(g, show_labels = FALSE) # hide node labels on dense graphs
plot(g, legend = FALSE) # suppress the legend
plot(g, legend_position = "bottomright")
plot(g, node_colors = c(Sample = "#000000")) # override type colorscitation("splitGraph")produces:
Korkmaz S (2026). splitGraph: Dataset Dependency Graphs for Leakage-Aware Evaluation. R package version 0.2.0. https://github.com/selcukorkmaz/splitGraph
MIT. See LICENSE.
The package prefers explicit failure over silent guessing. In particular:
validation_overrides
(e.g. allow_multi_subject_samples); the same override is
honored by both validate_graph() and
derive_split_constraints(mode = "subject")query_paths() defaults to a finite path-length cap so
traversal cannot explode on dense graphs; pass
max_length = Inf to opt outschema_version warns rather than failing
silently